ChatGPT带火了AI,那么,当GPT遇到自动驾驶,又会发生怎样的化学反应?
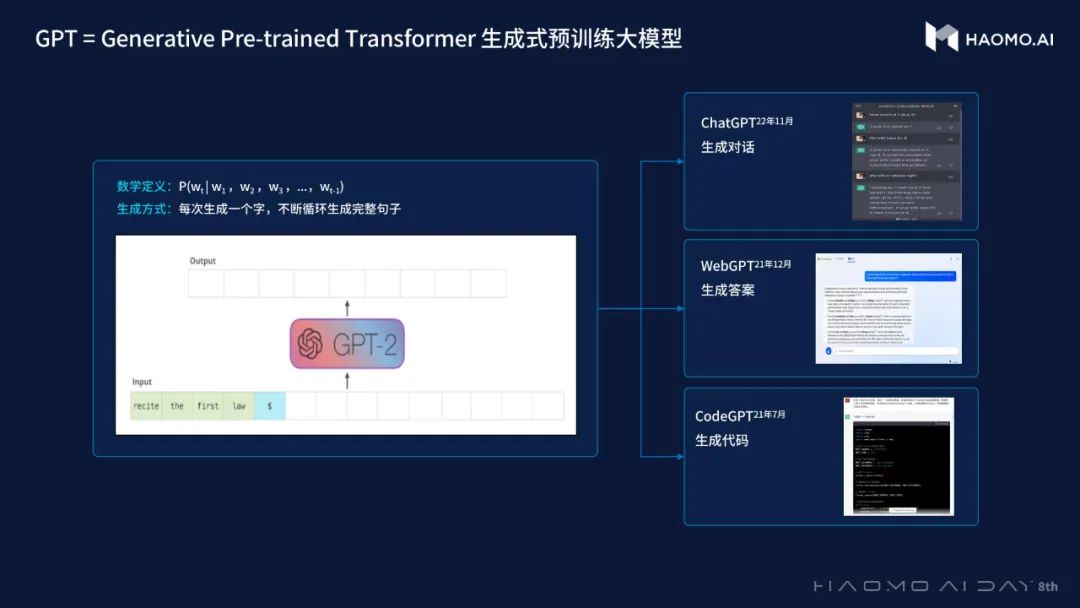
GPT全称Generative Pre-trained Transformer,即生成式预训练Transformer。简单概括即是一种基于互联网可用数据训练的文本生成深度学习模型。
4月11日,在第八届毫末AI DAY上,毫末CEO顾维灏正式发布了基于GPT技术的DriveGPT,中文名雪湖·海若。
DriveGPT能做到什么?又是如何构建的?顾维灏在AI DAY上都做了详细解读。此外,AI DAY还展示了毫末自动驾驶数据体系MANA的升级情况,主要是其在视觉感知能力上的进展。
01.
什么是DriveGPT?能实现什么?
顾维灏首先讲解了GPT的原理,生成式预训练Transformer模型本质上是在求解下一个词出现的概率,每一次调用都是从概率分布中抽样并生成一个词,这样不断地循环,就能生成一连串的字符,用于各种下游任务。
以中文自然语言为例,单字或单词就是Token,中文的Token词表有5万个左右。把Token输入到模型,输出就是下一个字词的概率,这种概率分布体现的是语言中的知识和逻辑,大模型在输出下一个字词时就是根据语言知识和逻辑进行推理的结果,就像根据一部侦探小说的复杂线索来推理凶手是谁。
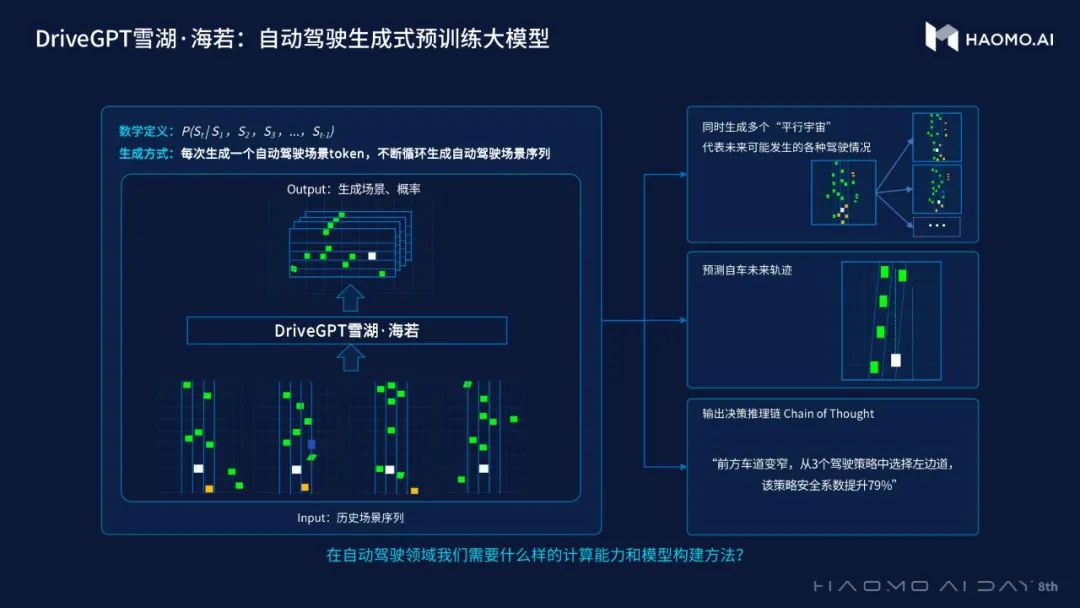
而作为适用于自动驾驶训练的大模型,DriveGPT雪湖·海若三个能力:
1.可以按概率生成很多个这样的场景序列,每个场景都是一个全局的场景,每个场景序列都是未来有可能发生的一种实际情况。
2.是在所有场景序列都产生的情况下,能把场景中最关注的自车行为轨迹给量化出来,也就是生成场景的同时,便会产生自车未来的轨迹信息。
3.有了这段轨迹之后,DriveGPT雪湖·海若还能在生成场景序列、轨迹的同时,输出整个决策逻辑链。
也就是说,利用DriveGPT雪湖·海若,在一个统一的生成式框架下,就能做到将规划、决策与推理等多个任务全部完成。
具体来看,DriveGPT雪湖·海若的设计是将场景Token化,毫末将其称为Drive Language。
Drive Language将驾驶空间进行离散化处理,每一个Token都表征场景的一小部分。目前毫末拥有50万个左右的Token词表空间。如果输入一连串过去已经发生的场景Token序列,模型就可以根据历史,生成未来所有可能的场景。
也就是说,DriveGPT雪湖·海若同样像是一部推理机器,告诉它过去发生了什么,它就能按概率推理出未来的多个可能。
一连串Token拼在一起就是一个完整的驾驶场景时间序列,包括了未来某个时刻整个交通环境的状态以及自车的状态。
有了Drive Language,就可以对DriveGPT进行训练了。
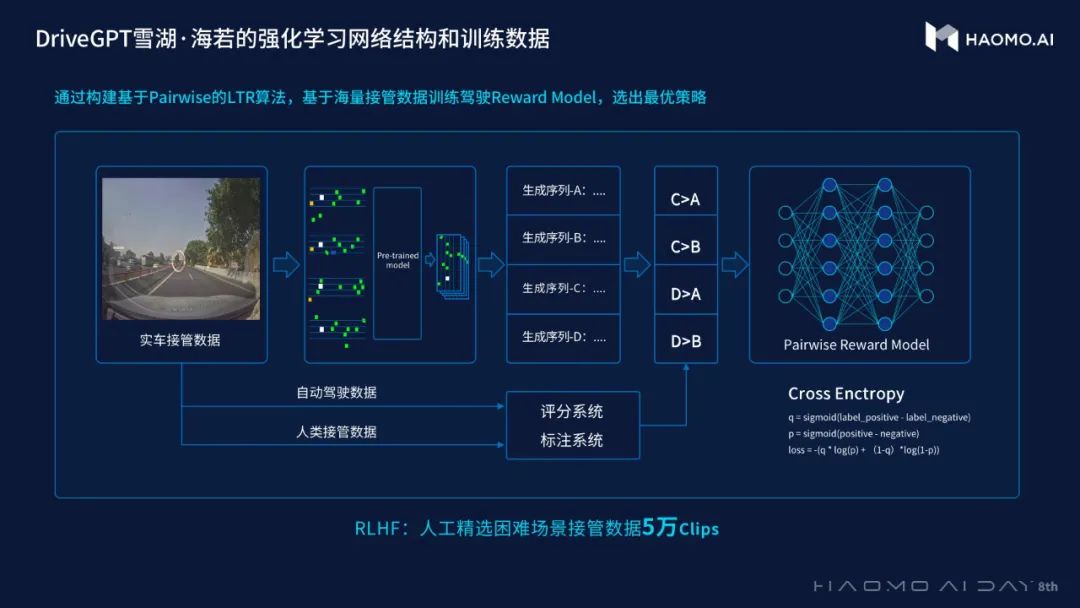
毫末对DriveGPT的训练过程首先是根据驾驶数据以及之前定义的驾驶尝试做一个大规模的预训练。
然后,通过在使用过程中接管或者不接管的场景,对预训练的结果进行打分和排序,训练反馈模型。也就是说利用正确的人类开法来替代错误的自动驾驶开法。
后续就是用强化学习的思路不断优化迭代模型。
在预训练模型上,毫末采用Decode-only结构的GPT模型,每一个Token用于描述某时刻的场景状态,包括障碍物的状态、自车状态、车道线情况等等。
目前,毫末的预训练模型拥有1200亿个参数,使用4000万量产车的驾驶数据,本身就能够对各种场景做生成式任务。
这些生成结果会按照人类偏好进行调优,在安全、高效、舒适等维度上做出取舍。同时,毫末会用部分经过筛选的人类接管数据,大概5万个Clips去做反馈模型的训练,不断优化预训练模型。
在输出决策逻辑链时,DriveGPT雪湖·海若利用了prompt提示语技术。输入端给到模型一个提示,告诉它“要去哪、慢一点还是快一点、并且让它一步步推理”,经过这种提示后,它就会朝着期望的方向去生成结果,并且每个结果都带有决策逻辑链。每个结果也会有未来出现的可能性。这样我们就可以选择未来出现可能性最大,最有逻辑的链条驾驶策略。
可以用一个形象的示例来解释DriveGPT雪湖·海若的推理能力。假设提示模型要“抵达某个目标点”,DriveGPT雪湖·海若会生成很多个可能的开法,有的激进,会连续变道超车,快速抵达目标点,有的稳重,跟车行驶到终点。这时如果提示语里没有其他额外指示,DriveGPT雪湖·海若就会按照反馈训练时的调优效果,最终给到一个更符合大部分人驾驶偏好的效果。
02.
实现DriveGPT毫末做了什么?
首先,DriveGPT雪湖·海若的训练和落地,离不开算力的支持。
今年1月,毫末就和火山引擎共同发布了其自建智算中心,毫末雪湖·绿洲MANA OASIS。OASIS的算力高达67亿亿次/秒,存储带宽2T/秒,通信带宽达到800G/秒。
当然,光有算力还不够,还需要训练和推理框架的支持。因此,毫末也做了以下三方面的升级。
一是训练稳定性的保障和升级。
大模型训练是一个十分艰巨的任务,随着数据规模、集群规模、训练时间的数量级增长,系统稳定性方面微小的问题也会被无限放大,如果不加处理,训练任务就会经常出错导致非正常中断,浪费前期投入的大量资源。
毫末在大模型训练框架的基础上,与火山引擎共同建立了全套训练保障框架,通过训练保障框架,毫末实现了异常任务分钟级捕获和恢复能力,可以保证千卡任务连续训练数月没有任何非正常中断,有效地保障了DriveGPT雪湖·海若大模型训练的稳定性。
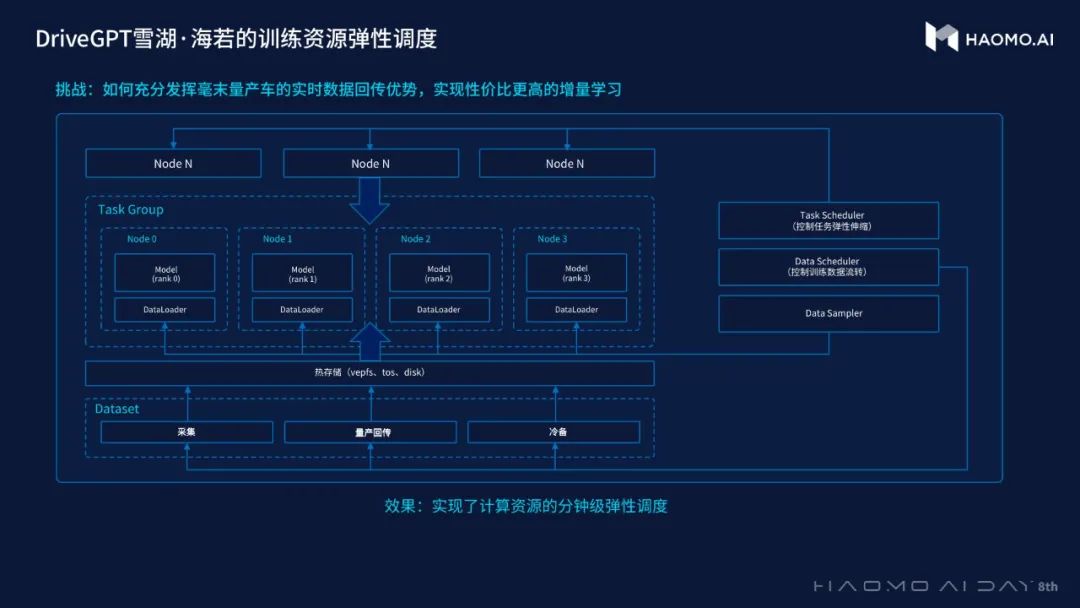
二是弹性调度资源的升级。
毫末拥有量产车带来的海量真实数据,可自动化的利用回传数据不断的学习真实世界。由于每天不同时段回传的数据量差异巨大,需要训练平台具备弹性调度能力,自适应数据规模大小。
毫末将增量学习技术推广到大模型训练,构建了一个大模型持续学习系统,研发了任务级弹性伸缩调度器,分钟级调度资源,集群计算资源利用率达到95%。
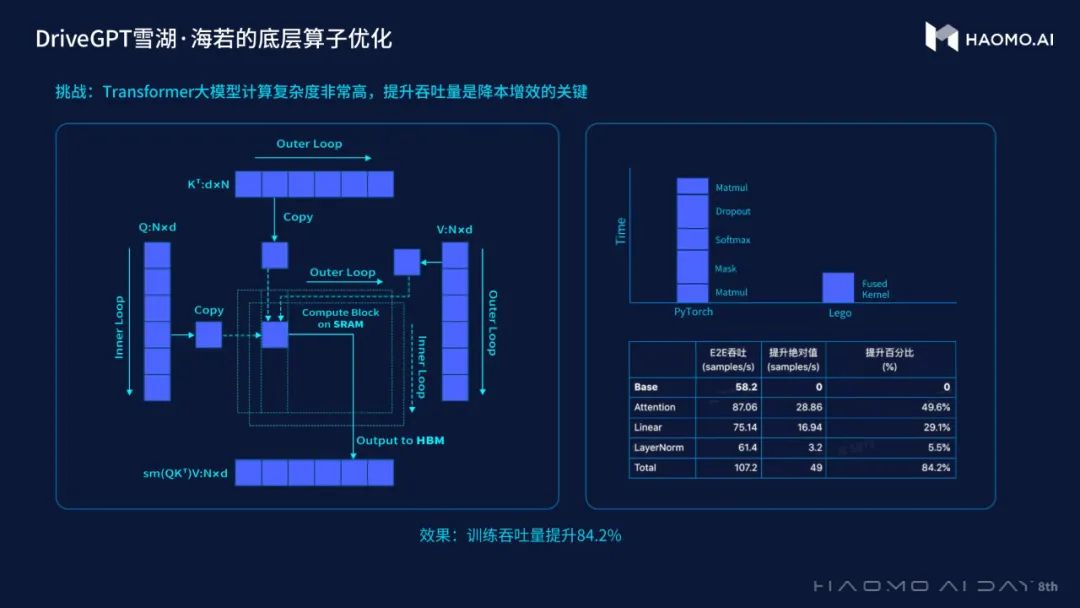
三是吞吐效率的升级。
在训练效率上,毫末在Transformer的大矩阵计算上,通过对内外循环的数据拆分、尽量保持数据在SRAM中来提升计算的效率。在传统的训练框架中,算子流程很长,毫末通过引入火山引擎提供的Lego算之库实现算子融合,使端到端吞吐提升84%。
有了算力和这三方面的升级,毫末可对DriveGPT雪湖·海若进行更好的训练迭代升级。
03.
MANA大升级,摄像头代替超声波雷达
毫末在2021年12月的第四届AI DAY上发布自动驾驶数据智能体系MANA,经过一年多时间的应用迭代,现在MANA迎来了全面的升级。
据顾维灏介绍,本次升级主要包括:
1.感知和认知相关大模型能力统一整合到DriveGPT。
2.计算基础服务针对大模型训练在参数规模、稳定性和效率方面做了专项优化,并集成到OASIS当中。
3.增加了使用NeRF技术的数据合成服务,降低Corner Case数据的获取成本。
4.针对多种芯片和多种车型的快速交付难题,优化了异构部署工具和车型适配工具。
前文我们已经详细介绍了DriveGPT相关的内容,以下主要来看MANA在视觉感知上的进展。
顾维灏表示,视觉感知任务的核心目的都是恢复真实世界的动静态信息和纹理分布。因此毫末对视觉自监督大模型做了一次架构升级,将预测环境的三维结构,速度场和纹理分布融合到一个训练目标里面,使其能从容应对各种具体任务。目前毫末视觉自监督大模型的数据集超过400万Clips,感知性能提升20%。
在泊车场景下,毫末做到了用鱼眼相机纯视觉测距达到泊车要求,可做到在15米范围内达测量精度30cm,2米内精度高于10cm。用纯视觉代替超声波雷达,进一步降低整体方案的成本。
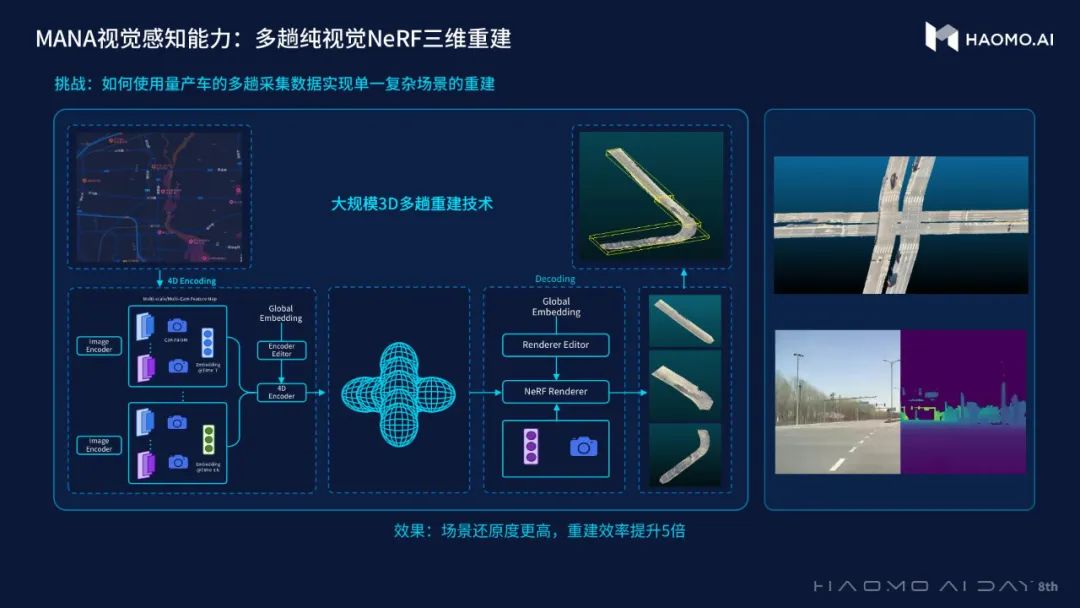
此外,在纯视觉三维重建方面,通过视觉自监督大模型技术,毫末不依赖激光雷达,就能将收集的大量量产回传视频转化为可用于BEV模型训练的带3D标注的真值数据。
通过对NeRF的升级,毫末表示可以做到重建误差小于10cm,并且对于场景中的动态物体也能做到很好的重建和渲染,达到肉眼基本看不出差异的程度。
此外,由于单趟重建有时会受到遮挡的影响,不能完整的还原三维空间,毫末也尝试了多趟重建的方式,即多辆车在不同时间经过同一地方,可以将数据合在一起做多趟重建。
顾维灏表示,目前毫末已经实现了更高的场景还原度,重建效率提升5倍,同时,还可在重建之后编辑场景合成难以收集的Corner Case。
此外,毫末也训练了一个可以在静态场景做虚拟动态物体编辑的模型,并且可以控制虚拟物体在场景中按照设定的轨迹运动,以更加高效的合成各种hardcase,使系统能够见识到足够多的corner case,低成本的测试自身的能力边界,提升NOH应对城市复杂交通环境的能力。
顾维灏表示,毫末DriveGPT雪湖·海若大模型的成果将在搭载毫末HPilot3.0的新摩卡DHT-PHEV上首发落地。
同时,顾维灏也表示,毫末DriveGPT雪湖·海若大模型将对生态伙伴开放。